Mykhailo Liepieshko
July 31, 2023 ・ Kubernetes
A Deep Dive into Kubernetes Networking
Kelsey Hightower's Kubernetes The Hard Way guide is not only effective but also highlights the simplicity and cleanliness in maintaining the networking aspect, including the Container Network Interface (CNI). However, it's important to note that Kubernetes networking can be confusing, particularly for beginners. It's worth mentioning that container networks, as a standalone concept, don't exist.
While there are some existing resources on this topic, they lack a comprehensive example that combines all the necessary command outputs to demonstrate the underlying processes. To address this gap, I decided to gather information from various sources to help you understand the interconnections and simplify the troubleshooting process. The example provided in Kubernetes The Hard Way serves as a reference, with IP addresses and configurations taken from there.
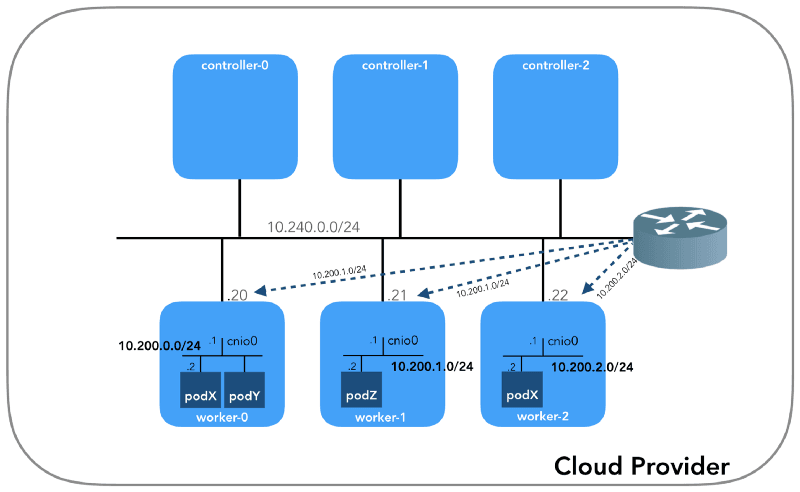
Now, let's focus on the final setup, which includes three controllers and three worker nodes:
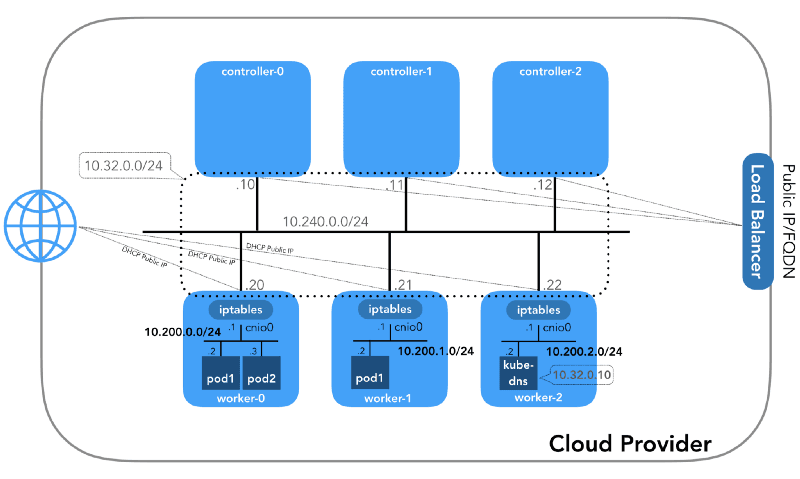
It's worth mentioning that there are also three private subnets in this setup. We will discuss each of them shortly. Keep in mind that these IP prefixes are specific to Kubernetes The Hard Way and hold only local significance. You have the flexibility to choose a different address block for your environment, following RFC 1918. An article dedicated to the case of IPv6 will be published separately on the blog.
Node network (10.240.0.0/24)
The internal network mentioned here encompasses all the nodes within it. In Google Cloud Platform (GCP), it is defined by the --private-network-ip flag, while in AWS, it is defined by the --private-ip-address option when allocating compute resources.
Controller node initialization in GCP
for i in 0 1 2; do
gcloud compute instances create controller-${i} \
# ...
--private-network-ip 10.240.0.1${i} \
# ...
done
Controller node initialization in AWS
for i in 0 1 2; do
declare controller_id${i}=`aws ec2 run-instances \
# ...
--private-ip-address 10.240.0.1${i} \
# ...
done
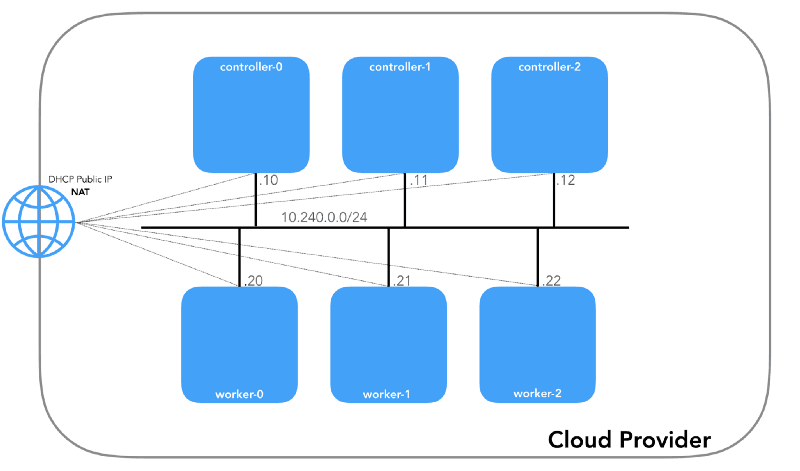
Every instance within the network will be assigned two IP addresses. The first is a private IP address from the node network. For the controllers, the private IP addresses are in the range of 10.240.0.1${i}/24, where ${i} represents the specific controller number. For the workers, the private IP addresses are in the range of 10.240.0.2${i}/24.
The instances also receive a public IP address assigned by the cloud provider. We will discuss the public IP addresses later when we cover the topic of NodePorts.
GCP
$ gcloud compute instances list
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING
worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING
AWS
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /'
10.240.0.10 34.228.XX.XXX controller-0
10.240.0.21 34.173.XXX.XX worker-1
...
All nodes should be able to ping each other if the security policies allow it (and if ping is installed on the host).
Pod Network (10.200.0.0/16)
This is the network where pods reside. Each worker node uses a subnet within this network. In our case, POD_CIDR=10.200.${i}.0/24 for worker-${i}.
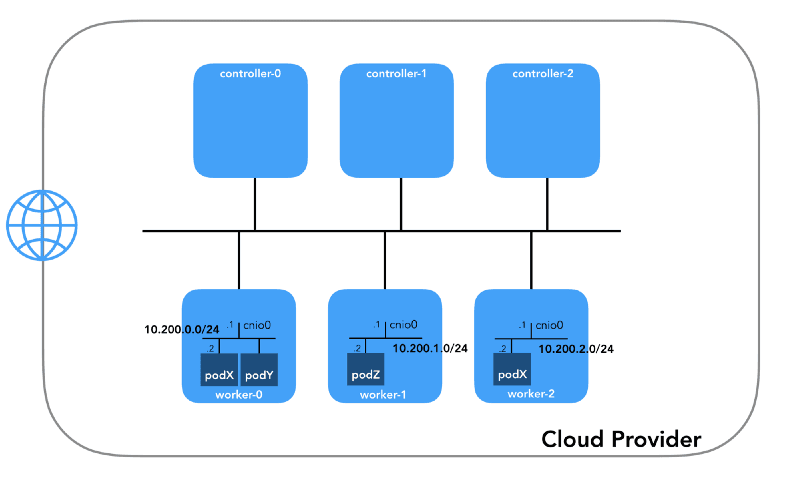
This network serves as the environment for pods. Each worker node in the cluster utilizes a subnet within this network. In our specific case, the subnet for worker-${i} is set as POD_CIDR=10.200.${i}.0/24.
To gain a comprehensive understanding of the setup, let's take a moment to delve into the Kubernetes networking model, which entails the following:
-
All containers should be able to communicate with each other directly, without the need for Network Address Translation (NAT).
-
All nodes should be able to communicate with all containers, and vice versa, without relying on NAT.
-
Containers should perceive their IP addresses in the same way as others do.
These requirements can be fulfilled using different approaches, and Kubernetes delegates the responsibility of network configuration to the Container Network Interface (CNI) plugin.
The CNI plugin is responsible for adding a network interface in the container's namespace (e.g., one end of a veth pair) and making necessary changes on the host (e.g., attaching the other end of the veth pair to a bridge). It then assigns an IP to the interface and configures routes according to the 'IP Address Management' section by invoking the appropriate IPAM. (IP Address Management) plugin (from the Container Network Interface Specification).
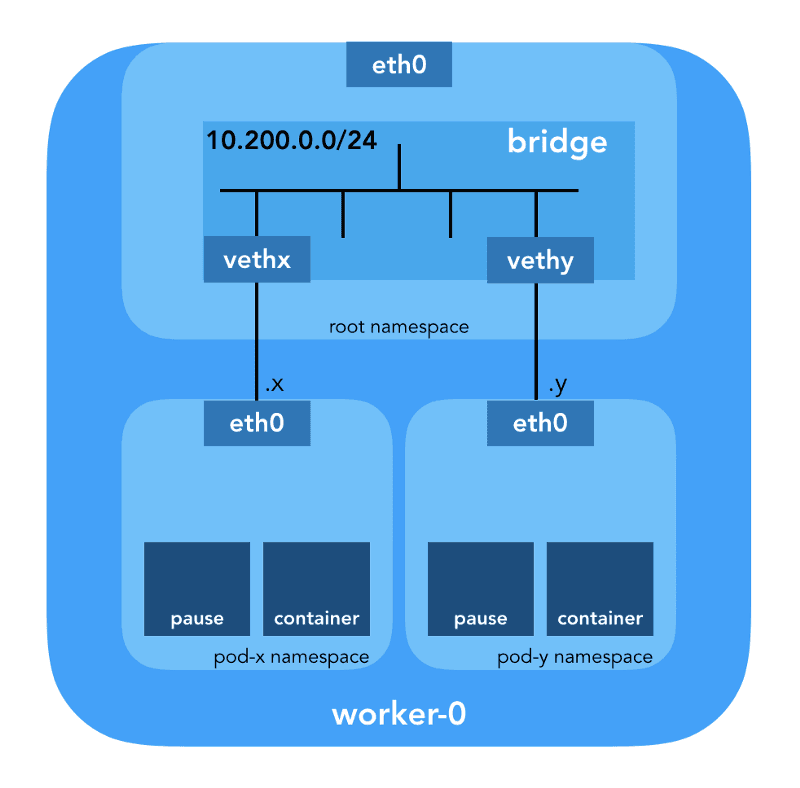
Network namespaces
A namespace wraps a global system resource in an abstraction that makes it visible to processes within that namespace as though they had their isolated instance of the global resource. Changes to the global resource are visible to other processes that are members of the namespace, but are not visible to processes outside of the namespace. (from the namespaces man page).
Linux provides seven different namespaces (Cgroup, IPC, Network, Mount, PID, User, UTS). Network namespaces (CLONE_NEWNET) define the network resources available to a process:
Linux offers seven distinct namespaces, including Cgroup, IPC, Network, Mount, PID, User, and UTS namespaces. Among these, the Network namespace (CLONE_NEWNET) is specifically responsible for managing the network-related resources accessible to a process.
Each network namespace has its own network devices, IP addresses, IP routing tables, /proc/net directory, port numbers, and so on. (from the "Namespaces in operation" article).
Virtual Ethernet Devices (Veth)
A virtual network pair (veth) provides an abstraction in the form of a 'pipe' that can be used to create tunnels between network namespaces or to bridge to a physical network device in a different network namespace. When a namespace is released, all veth devices within it are destroyed (from the network namespaces man page).
In the context of a Kubernetes cluster, it is crucial to acknowledge the existence of multiple networking plugins available for Kubernetes. Among these plugins, the Container Network Interface (CNI) plugin plays a significant role in managing networking within the cluster.
Within the Kubernetes cluster, each node has the Kubelet, which informs the container runtime about the selected networking plugin to be used. The container runtime then collaborates with the CNI plugin to handle the configuration of networking.
The CNI plugin acts as an intermediary layer between the container runtime and the actual networking implementation. It facilitates communication and coordination between the container runtime and the networking infrastructure. The primary responsibility of the CNI plugin is to configure the network by managing network devices, IP addresses, routing tables, and other essential networking components.
The CNI plugin is selected by passing the command-line option --network-plugin=cni to the Kubelet. The Kubelet reads the file from
--cni-conf-dir(default is/etc/cni/net.d) and uses the CNI configuration from that file to set up the network for each pod (from the Network Plugin Requirements).
The actual CNI plugin binaries are located in --cni-bin-dir (default is /opt/cni/bin).
Note that the kubelet.service invocation parameters include --network-plugin=cni:
[Service]
ExecStart=/usr/local/bin/kubelet \\
--config=/var/lib/kubelet/kubelet-config.yaml \\
--network-plugin=cni \\
...
In the Kubernetes architecture, the creation of a network namespace for a pod occurs before any networking plugins are invoked. This is accomplished by employing a special container known as the "pause" container, which acts as the "parent container" for all other containers within the pod. This concept is highlighted in the article "The Almighty Pause Container."
Once the network namespace is established, Kubernetes proceeds to execute the Container Network Interface (CNI) plugin to connect the pause container to the network. By doing so, all containers within the pod utilize the network namespace (netns) of this pause container. This approach enables efficient network communication and management within the pod, ensuring that all containers share the same network context.
{
"cniVersion": "0.3.1",
"name": "bridge",
"type": "bridge",
"bridge": "cnio0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"ranges": [
[{"subnet": "${POD_CIDR}"}]
],
"routes": [{"dst": "0.0.0.0/0"}]
}
}
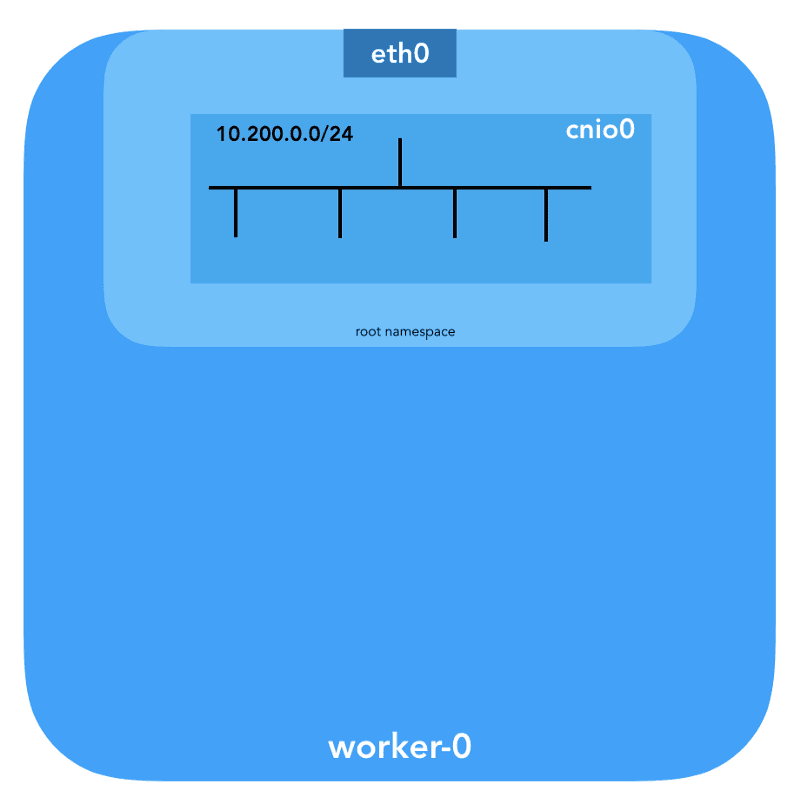
The configuration used for CNI specifies the use of the bridge plugin to configure a Linux software bridge (L2) in the root namespace named cnio0 (default name is cni0), which acts as the gateway ("isGateway": true).
Additionally, a veth pair will be set up to connect the pod to the newly created bridge.
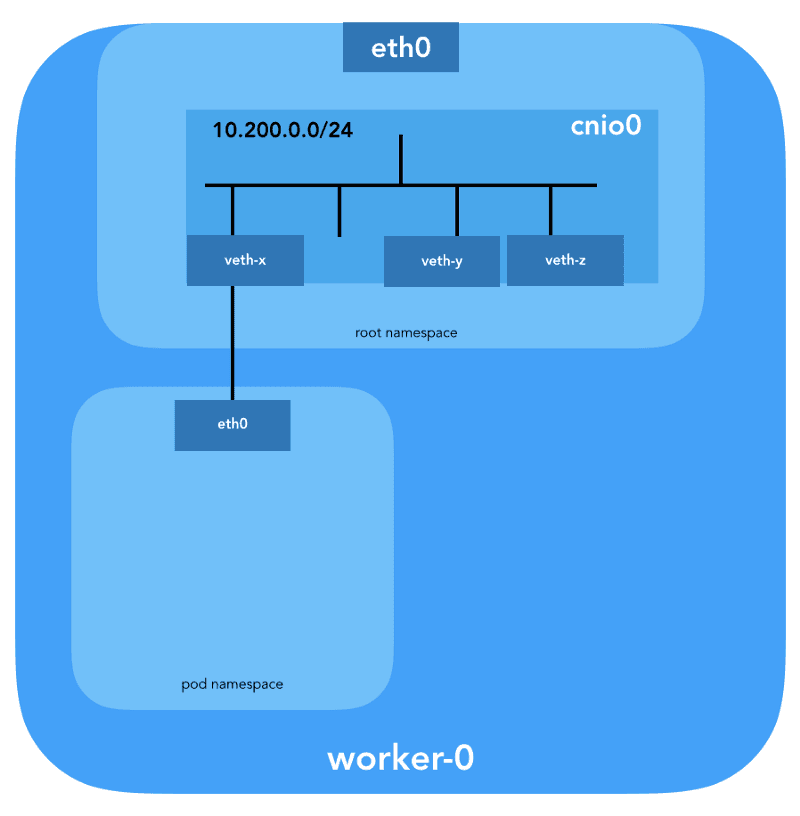
To assign Layer 3 (L3) information such as IP addresses within a pod, the IP Address Management (IPAM) plugin is invoked. In this scenario, the host-local IPAM plugin type is utilized, which stores state locally on the host's filesystem to ensure unique IP addresses are assigned to containers residing on a single host. This information is returned by the IPAM plugin to the preceding plugin, which in this case is the bridge plugin.
The bridge plugin uses the IPAM-provided information to configure all specified routes, as defined in the configuration file. If a gateway (gw) is not explicitly specified, it is obtained from the subnet. Additionally, the default route is configured within the pod's network namespace, directing traffic to the bridge. The bridge itself is configured with the first IP address of the pod's subnet.
It's important to note that masquerading (ipMasq) of outgoing traffic from the pod network is requested. Although NAT is not technically required in this scenario, it is configured in “Kubernetes The Hard Way” for completeness. Consequently, the bridge plugin's iptables rules are set up accordingly. Any packets originating from the pod and destined for addresses outside the range of 224.0.0.0/4 will undergo masquerading. This configuration deviates from the ideal requirement of "all containers can communicate with any other container without using NAT. "Well, we will prove why NAT is not needed further on…”

Pod Routing
Now, let's proceed with the configuration of pods. We'll start by examining all the network namespaces on one of the worker nodes. Afterward, we'll analyze one specific namespace following the creation of the nginx deployment.
To view the network namespaces, we can use the lsns command with the -t option, which allows us to filter by the desired namespace type, in this case, net.
ubuntu@worker-0:~$ sudo lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026532089 net 113 1 root /sbin/init
4026532280 net 2 8046 root /pause
4026532352 net 4 16455 root /pause
4026532426 net 3 27255 root /pause
By using the -i option with ls, we can find their inode numbers.
ubuntu@worker-0:~$ ls -1i /var/run/netns
4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af
4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c
4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0
We can also list all network namespaces using ip netns:
ubuntu@worker-0:~$ ip netns
cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2)
cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1)
cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)
To see all the processes running in the network namespace cni-912bcc63-712d-1c84-89a7-9e10510808a0 (4026532426), you can execute a command like this:
ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p
PID TTY STAT TIME COMMAND
27255 ? Ss 0:00 /pause
27331 ? Ss 0:00 nginx: master process nginx -g daemon off;
27355 ? S 0:00 nginx: worker process
It's evident that besides the pause container, we have also launched nginx in this pod. The pause container shares the net and ipc namespaces with all the other containers in the pod. Let's note the PID of the pause container as 27255, we will come back to it later.
Now let's see what information kubectl can provide about this pod:
$ kubectl get pods -o wide | grep nginx
nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0
More detailed:
$ kubectl describe pods nginx-65899c769f-wxdx6
Name: nginx-65899c769f-wxdx6
Namespace: default
Node: worker-0/10.240.0.20
Start Time: Thu, 05 Jul 2018 14:20:06 -0400
Labels: pod-template-hash=2145573259
run=nginx
Annotations: <none>
Status: Running
IP: 10.200.0.4
Controlled By: ReplicaSet/nginx-65899c769f
Containers:
nginx:
Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7
Image: nginx
...
We can see the pod name nginx-65899c769f-wxdx6 and the ID of one of its containers (nginx), but there is no mention of the pause container yet. Let's dig deeper into the worker node to gather all the relevant information. Please note that in Kubernetes The Hard Way, Docker is not used, so we will use the ctr command-line utility from containerd to obtain container details.
ubuntu@worker-0:~$ sudo ctr namespaces ls
NAME LABELS
k8s.io
Knowing the containerd namespace (k8s.io), we can retrieve the container ID of nginx:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
… and pause too:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause
0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
The container ID of nginx, ending in ...983c7, matches what we obtained from kubectl. Now let's see if we can find out which pause container belongs to the nginx pod:
ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls
TASK PID STATUS
...
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNING
Please note that processes with PIDs 27331 and 27355 are running in the network namespace cni-912bcc63-712d-1c84-89a7-9e10510808a0.
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6
{
"ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6",
"Labels": {
"io.cri-containerd.kind": "sandbox",
"io.kubernetes.pod.name": "nginx-65899c769f-wxdx6",
"io.kubernetes.pod.namespace": "default",
"io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382",
"pod-template-hash": "2145573259",
"run": "nginx"
},
"Image": "k8s.gcr.io/pause:3.1",
...
… and:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7
{
"ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7",
"Labels": {
"io.cri-containerd.kind": "container",
"io.kubernetes.container.name": "nginx",
"io.kubernetes.pod.name": "nginx-65899c769f-wxdx6",
"io.kubernetes.pod.namespace": "default",
"io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382"
},
"Image": "docker.io/library/nginx:latest",
...
Now we know exactly which containers are running in this pod (nginx-65899c769f-wxdx6) and in the network namespace (cni-912bcc63-712d-1c84-89a7-9e10510808a0).
-
nginx (ID:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7); -
pause (ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6).
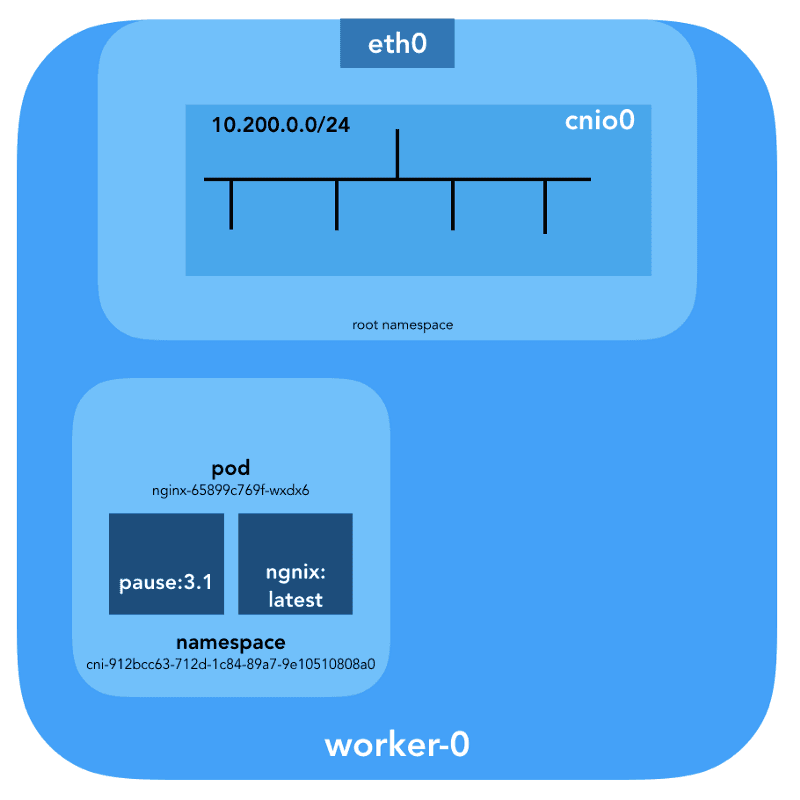
How is this pod (nginx-65899c769f-wxdx6) connected to the network? Let's use the previously obtained PID 27255 from the pause container to run commands within its network namespace (cni-912bcc63-712d-1c84-89a7-9e10510808a0):
ubuntu@worker-0:~$ sudo ip netns identify 27255
cni-912bcc63-712d-1c84-89a7-9e10510808a0
To achieve that, we can use nsenter with the -t option to specify the target PID and -n without specifying a file to enter the network namespace of the target process (27255). Here's what the command ip link show will provide:
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
… and ifconfig eth0:
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0
inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link>
ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet)
RX packets 540 bytes 42247 (42.2 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 177 bytes 16530 (16.5 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Thus, it is confirmed that the IP address obtained earlier through kubectl get pod is configured on the eth0 interface of the pod. This interface is part of a veth pair, with one end in the pod's namespace and the other end in the root namespace. To find the interface of the other end, we can use ethtool:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0
NIC statistics:
peer_ifindex: 7
We can see that the ifindex of the peer is 7. Let's verify that it is in the root namespace using ip link:
ubuntu@worker-0:~$ ip link | grep '^7:'
7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group default
To confirm this further, let's check:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex
7
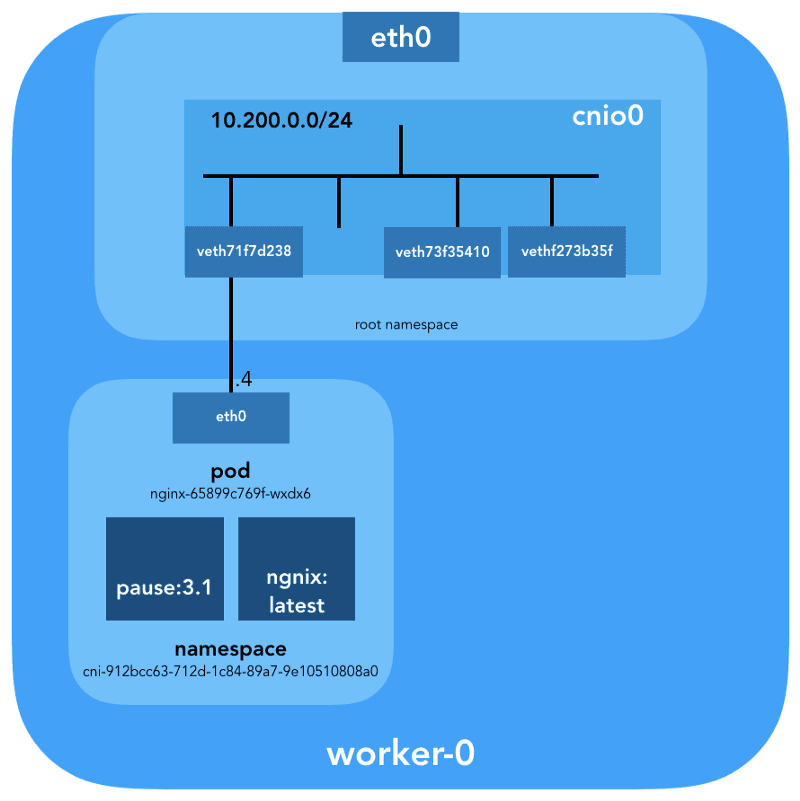
Great, we have a clear understanding of the virtual link now. Let's use brctl to see who else is connected to the Linux bridge.
ubuntu@worker-0:~$ brctl show cnio0
bridge name bridge id STP enabled interfaces
cnio0 8000.0a580ac80001 no veth71f7d238
veth73f35410
vethf273b35f
So, the overall picture looks like this:
Routing Verification
How is traffic actually being routed? Let's take a look at the routing table in the pod's network namespace:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show
default via 10.200.0.1 dev eth0
10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4
At least we know how to reach the root namespace (default via 10.200.0.1). Now let's examine the host's routing table:
ubuntu@worker-0:~$ ip route list
default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100
10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1
10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20
10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100
In a Kubernetes cluster, the VPC Router serves as the implicit router for the Virtual Private Cloud (VPC). Typically, it is assigned the second address from the main IP address range of the subnet. However, it's important to note that the VPC Router doesn't automatically know how to reach each pod's network.
To establish connectivity between the VPC Router and the pod networks, routes need to be configured. This can be accomplished either by the CNI plugin itself or manually, as demonstrated in the guide you mentioned. In the case of AWS, the AWS CNI plugin is likely responsible for handling this configuration on our behalf. It's worth mentioning that there are multiple CNI plugins available, and the example we're discussing here focuses on a simple network configuration scenario.
Deep Dive into NAT
Let's create two identical busybox containers using the command kubectl create -f busybox.yaml with a Replication Controller.
apiVersion: v1
kind: ReplicationController
metadata:
name: busybox0
labels:
app: busybox0
spec:
replicas: 2
selector:
app: busybox0
template:
metadata:
name: busybox0
labels:
app: busybox0
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
restartPolicy: Always
After creating the containers, we can observe the following:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1
busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0
...
The ping from one container to another should be successful.
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15
PING 10.200.1.15 (10.200.1.15): 56 data bytes
64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms
64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms
--- 10.200.1.15 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.440/0.484/0.528 ms
To understand the traffic flow, we can examine the packets using tools like tcpdump or conntrack:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15
icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
The source IP from the pod (10.200.0.21) is translated to the node's IP address (10.240.0.20).
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15
icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
In iptables, we can see that the counters are increasing:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
...
5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */
Zeroing chain `POSTROUTING'
However, if we remove "ipMasq": true from the CNI plugin configuration, we can observe the following (this operation is purely for educational purposes, and we do not recommend modifying the configuration on a production cluster!):
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0
busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1
...
The ping should still be successful.
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13
PING 10.200.1.6 (10.200.1.6): 56 data bytes
64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms
64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms
--- 10.200.1.6 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.427/0.471/0.515 ms
And in this case, without using NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13
icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
So, we have verified that "all containers can communicate with each other without using NAT."
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13
icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Cluster Network (10.32.0.0/24)
In the example with the busybox pod, you might have observed that the assigned IP addresses to the busybox pod varied each time. However, if you require consistent accessibility to the containers from other pods, relying solely on the current pod IP addresses won't suffice due to their dynamic nature.
To address this requirement, you need to configure a Service resource in Kubernetes. The Service acts as a proxy or abstraction layer for requests to a group of ephemeral pods. It provides a stable and consistent endpoint for other pods or external services to interact with.
By creating a Service, you can define a specific set of pods or selector criteria that the Service should route requests to. The Service will automatically manage the network routing and load balancing, ensuring that the requests reach the appropriate pods, even if their IP addresses change due to scaling or rescheduling.
Using a Service allows you to decouple the accessing pods from the underlying pod IP addresses, providing a reliable and scalable way to access and communicate with the containers within the Kubernetes cluster.
A Service in Kubernetes is an abstraction that defines a logical set of pods and a policy by which to access them. (from the Kubernetes Services documentation)
There are different ways to expose a service, and the default type is ClusterIP, which assigns an IP address from the cluster CIDR block (i.e., accessible only from within the cluster). One such example is the DNS Cluster Add-on, configured in Kubernetes The Hard Way.
# ...
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "KubeDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.32.0.10
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
# ...
kubectl shows that the Service keeps track of endpoints and performs their translation:
$ kubectl -n kube-system describe services
...
Selector: k8s-app=kube-dns
Type: ClusterIP
IP: 10.32.0.10
Port: dns 53/UDP
TargetPort: 53/UDP
Endpoints: 10.200.0.27:53
Port: dns-tcp 53/TCP
TargetPort: 53/TCP
Endpoints: 10.200.0.27:53
...
How exactly does it work?... It's iptables again. Let's go through the rules created for this example. You can see the full list of rules using the iptables-save command.
As soon as packets are generated by a process (OUTPUT) or arrive at a network interface (PREROUTING), they go through the following iptables chains:
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
The following rules match TCP packets sent to port 53 of 10.32.0.10 and translate them to the receiver 10.200.0.27 with port 53:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4
-A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H
-A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53
The same applies to UDP packets (receiver 10.32.0.10:53 → 10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
-A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG
-A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53
There are other types of Services in Kubernetes. In particular, Kubernetes The Hard Way mentions NodePort — see the Smoke Test: Service.
kubectl expose deployment nginx --port 80 --type NodePort
NodePort exposes the service on each node's IP address by assigning it to a static port (hence the name NodePort). The NodePort service can be accessed from outside the cluster. You can check the allocated port (in this case, 31088) using kubectl:
$ kubectl describe services nginx
...
Type: NodePort
IP: 10.32.0.53
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 31088/TCP
Endpoints: 10.200.1.18:80
...
Now the pod is accessible from the internet as http://${EXTERNAL_IP}:31088/. Here, EXTERNAL_IP is the public IP address of any worker instance. In this example, I used the public IP address of worker-0. The request is received by the node with the internal IP address 10.240.0.20 (the public NAT is handled by the cloud provider), but the service is actually running on another node (worker-1, as can be seen from the endpoint's IP address — 10.200.1.18):
ubuntu@worker-0:~$ sudo conntrack -L | grep 31088
tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1
The packet is forwarded from worker-0 to worker-1, where it finds its recipient:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80
tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1
Is this scheme ideal? Perhaps not, but it works. In this case, the programmed iptables rules are as follows:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA
-A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H
-A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80
In other words, the address for packets with port 31088 is translated to 10.200.1.18. The port is also translated from 31088 to 80.
We haven't touched upon another type of service — LoadBalancer — which makes the service publicly accessible through a cloud provider's load balancer, but this article is already quite extensive.
Conclusion
Indeed, the topic of Kubernetes networking is vast and encompasses various advanced concepts and technologies. While we have covered some fundamental aspects, there is still much more to explore.
In the future, you can delve into topics such as IPv6 integration within Kubernetes, IPVS (IP Virtual Server) for load balancing, eBPF (extended Berkeley Packet Filter) for enhanced networking capabilities, and several other interesting and relevant CNI plugins.
Each of these areas provides unique insights and solutions for different networking challenges within Kubernetes. By delving deeper into these topics, you can gain a more comprehensive understanding of Kubernetes networking and leverage advanced features and technologies to optimize and enhance your cluster's network performance and functionality.
Reference: Leiva, Nicolas. "Kubernetes Networking: Behind the Scenes."
Related Reading
- Kubernetes
- Infrastructure